1.提取绿色区域¶
1.读取图片,进行高斯模糊,并转化为hsv图片,这是为了方便颜色的提取。
frame = cv2.imread(r"C:\Users\xjy\Desktop\hanjia\1.jpg")
gs_frame = cv2.GaussianBlur(frame, (5, 5), 0) # 高斯模糊
hsv = cv2.cvtColor(gs_frame, cv2.COLOR_BGR2HSV) # 转化成HSV图像

2.进行腐蚀减少干扰,去除背景,转化为二值化图片
ball_color = 'green'
#三种颜色在hsv模式下的范围
color_dist = {'red': {'Lower': np.array([0, 60, 60]), 'Upper': np.array([6, 255, 255])},
'blue': {'Lower': np.array([100, 80, 46]), 'Upper': np.array([124, 255, 255])},
'green': {'Lower': np.array([35, 43, 35]), 'Upper': np.array([90, 255, 255])},
}
erode_hsv = cv2.erode(hsv, None, iterations=2) # 腐蚀
inRange_hsv = cv2.inRange(erode_hsv, color_dist[ball_color]['Lower'], color_dist[ball_color]['Upper'])

3.获取矩形的轮廓,提取最小外接矩形的坐标,在原图上裁剪出来
inRange_hsv = cv2.inRange(erode_hsv, color_dist[ball_color]['Lower'], color_dist[ball_color]['Upper'])
cnts = cv2.findContours(inRange_hsv.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[-2]#获取图片中的轮廓
c = max(cnts, key=cv2.contourArea) #在边界中找出面积最大的区域
rect = cv2.minAreaRect(c) # 绘制出该区域的最小外接矩形
box = cv2.boxPoints(rect) # 记录该矩形四个点的位置坐标
box = np.int0(box) #将坐标转化为整数
x, y, w, h = cv2.boundingRect(box) # 获取最小外接轴对齐矩形的坐标
image = frame[y:y + h, x:x + w] #获取roi区域

2.对剪切后的图片进行处理¶
1.转为二值化图片,进行膨胀
# 灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 二值化
ret, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)
#变成白底黑字
cv2.bitwise_not(binary, binary)
#进行膨胀运算,方便后期轮廓检测
kernel = np.ones((5, 5), np.uint8)
bin2 = cv2.erode(binary, kernel)
cv2.imshow("pz",bin2)
cv2.waitKey(0)

2.对图片中较小的轮廓进行填充,减小干扰
# 小轮廓去除
contours, hierarchy = cv2.findContours(bin2, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
fill = []
for contour in contours:
#计算轮廓周长
area = cv2.contourArea((contour))
#如果周长小于一个值就添加进列表
if area < 250:
fill.append(contour)
#将图中轮廓周长小的部位填涂
bin2 = cv2.fillPoly(bin2, fill, (255, 255, 255))
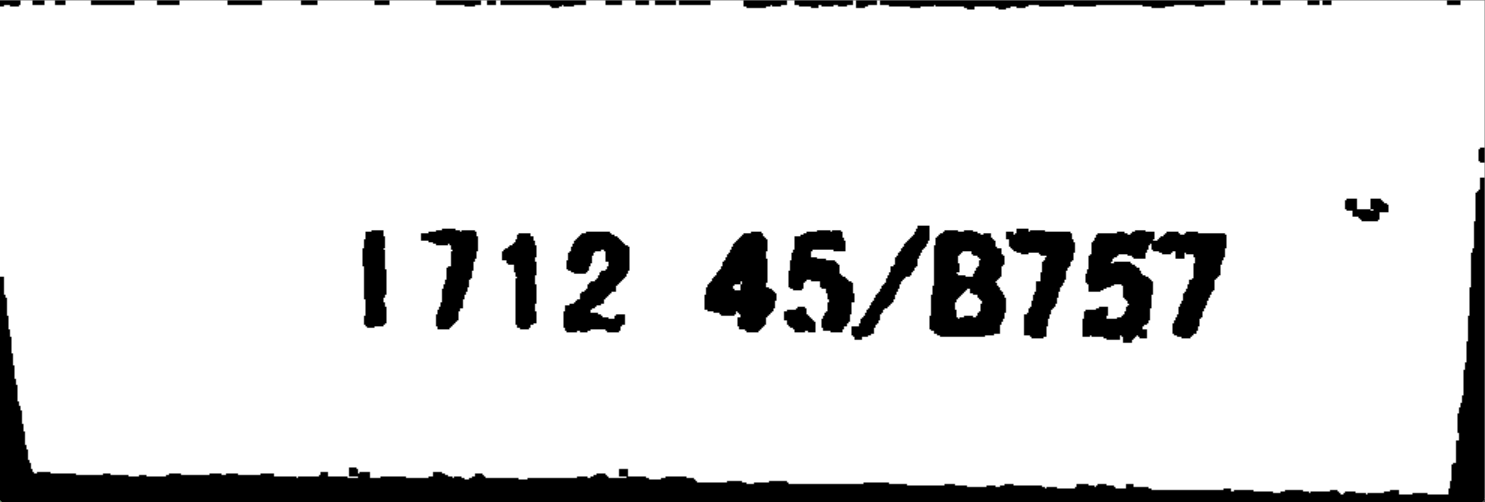
3.选取一定面积大小的轮廓
# 轮廓检测
contours, hierarchy = cv2.findContours(bin2, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
draw_img2 = bin2.copy()
# 筛选轮廓:
need_contours = []
for contour in contours:
#计算轮廓的左上角坐标xy和宽高wh
x, y, w, h = cv2.boundingRect(contour)
#计算矩形面积
rectangle_area = w * h
#一定大小的面积才圈出轮廓
if (rectangle_area < 10000 and rectangle_area > 600):
need_contours.append(contour)
res = cv2.drawContours(draw_img2, need_contours, -1, (255, 0, 0), 2)
cv2.imshow("res", res)
cv2.waitKey(0)

4.对剩余轮廓画矩形
draw_img2 = image.copy()
for contour in need_contours:
# 计算轮廓的左上角坐标xy和宽高wh
x, y, w, h = cv2.boundingRect(contour)
#记录数字的轮廓坐标
xy.append([x,y,x+w,y+h])
#在每个轮廓外花矩形框
draw_img2 = cv2.rectangle(draw_img2, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.imshow("img3", draw_img2)

3.剪切数字¶
#根据x的值比较,x之间差大于100的图片为竖图,需要根据y来排序
if abs(xy[0][0]-xy[-1][0] )>100:
xy=sorted(xy, key=lambda x: x[0])
else:
xy=sorted(xy, key=lambda x: x[1])
#保存每个数字的图片
for i in range(len(xy)):
cat = bin2[xy[i][1]:xy[i][3],xy[i][0]:xy[i][2]]
size = (40, 30)
cat = cv2.resize(cat, size)
cv2.imwrite(r"./cat/{}.jpg".format(i+1), cat)
4.读取模板图片¶
# 模板文件夹路径
path = './moban'
templates = []
template_ids = []
filelist = os.listdir(path)
for files in filelist:
Olddir = os.path.join(path, files)
# 如果是文件夹
if os.path.isdir(Olddir):
# 遍历小文件夹
filelist = os.listdir(Olddir)
for files in filelist:
Olddir2 = os.path.join(Olddir, files)
templates.append(cv2.imread(Olddir2, 0))
a = files.find("_")
template_ids.append(files[0:a])
5.进行模板匹配并输出结果¶
# 遍历模板列表
list2=[]
i=1
flag=False
while i<=len(xy):
img_path=r"C:\Users\xjy\Desktop\hanjia\cat\{}.jpg".format(i)
frame = cv2.imread(img_path)
#灰度图
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
i+=1
for template, template_id in zip(templates, template_ids):
#进行模板匹配
res = cv2.matchTemplate(frame, template, cv2.TM_CCOEFF_NORMED)
#设置匹配度
threshold = 0.8
loc = np.where(res >= threshold)
# 为每个匹配到的位置添加信息到结果字典
for pt in zip(*loc[::-1]):
if template_id=="10":
list2.append("/")
else:
list2.append(template_id)
flag=True
break
if flag==True:
flag=False
break
result = ''.join(list2)
print(result)
ocr识别¶
下载ocr识别
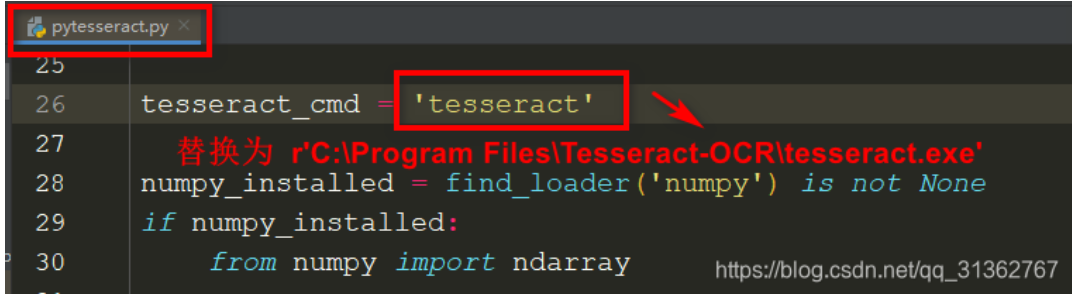
https://digi.bib.uni-mannheim.de/tesseract/
下载完后在终端下载pytesseract库,并修改参数,地址为你安装的地址
1.识别
test_message = Image.fromarray(bin2)
text = pytesseract.image_to_string(test_message,lang='eng')
print(f'识别结果:{text}')
结果:
